Very well, I’ve been had. I lost all my bitcoin savings.
Don’t worry, it was not much. Approximately 0.0113 bitcoins. Just over a hundred US dollars at current exchange rates. And it’s not like I didn’t know from the onset that something fishy was going on. Of course I was not planning to hand over my hundred bucks to a scam artist, but I figured the learning experience was worth the risk. I had no idea how things would play out, except for one thing: I knew I was not going to get richer, but my risk was limited to my meager bitcoin holdings.
Here is how it began. I became acquainted with an Neale H. Spark* on Quora. At first, we exchanged some private messages, in part about some of the answers I wrote. But soon, he started talking about the business he is in, cryptocurrency. He seemed legit: I looked him up. A cryptocurrency expert, member of a listed cryptocurrency company’s advisory board. He asked if I wanted to invest some bitcoins into cloud mining, because supposedly, I can make “8% a day”.
OK, red flags are up. Nobody, and I mean nobody, is paying you 8% daily interest. That this was a scam, of that I had no doubt, but I just couldn’t resist: I had to understand how the scheme worked.
It so happened that I actually had some bitcoins, those 0.0113 BTC, in a bitcoin wallet. So what the heck… let’s play along.
As soon as I agreed to become his victim (not that he called me that, mind you), this Mr. Spark kindly set up a “mining enabled” bitcoin account for me at blockchain.com. He provided me with all necessary details and soon enough, I was able to manage the account. I then transferred my bitcoin holdings from my other wallet to this one.
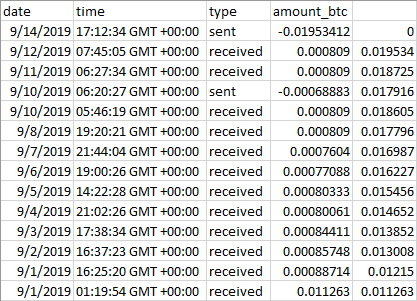
And within 24 hours, I received about 0.0008 bitcoins. And again, 24, 48, 72 hours later. I was told by Mr. Spark that this money is not completely free money: that there will be a “mining fee”, which sounded odd because how can they charge any fee to my bitcoin account? But you know what, let’s see what happens. Indeed, after about a week of regular, daily payments, four days ago I actually got charged about 0.0008 bitcoins. But the payments continued: after two more payments, my bitcoin holdings were getting close to double my initial investment.
Meanwhile, Mr. Spark called me several times on the phone. It was always a bad connection, suggesting to me that he was using a VoIP phone, but for what it’s worth, his calls came from a California number consistent with his place of residence. He was advising me that I should invest a lot more; that investors who put in a full bitcoin or more (that would be $10,000 US) are doing much better. I told him that I’d think about it. He asked when I might make my decision. I said he’d be the first to know. He did not sound happy.
Indeed, the phone calls stopped and for the past two days, I received no e-mail notification of payments in my bitcoin wallet either. So earlier today, I went to check the wallet, and whoops: all my bitcoins are gone. The wallet has been zeroed out two days ago.
I sent this Mr. Spark a Quora message but I am not expecting a reply. On the other hand, I think I can reconstruct what actually happened, so my bitcoins were, after all, well spent: I did learn some intriguing details.
For starters, I am pretty certain that the Quora account doesn’t actually belong to the real Neale H. Spark. I tried to find information online about Mr. Spark but I was unable to locate a valid e-mail address or social media account. The person is undoubtedly real, mentioned in a 201█ press release by G█████ T███████████ as a newly minted member of their advisory board. But Mr. Spark seems like a rather private person with little visible online presence.
The Quora account was only created about a month ago. It has very low activity.
The aggressive sales tactics seemed odd from a noted expert, and represented another indication of fraud. But how exactly was the fraud committed?
Here is how. It all started when “Mr. Spark” kindly set up that “mining-enabled” Bitcoin wallet for me on blockchain.com. I knew something was not kosher (what exactly is a “mining enabled” account, pray tell?) but in my ignorance of the technical details of cryptocurrency wallets, I could not quite put my finger on it. When I received the account info, everything checked out and I was able to secure the account, restricting transactions with two-factor authentication and even by IP address.
However, unbeknownst to me, “Mr. Spark” must have copied down the blockchain.com wallet backup phrase: twelve words. The company warns me: Anyone with access to my backup phrase can access my funds. What I didn’t know is that the backup phrase can be used anywhere. They need not access the wallet through blockchain.com; with the appropriate cryptocurrency software, they can recreate the wallet and empty it.
Which means that my entire blockchain.com wallet was compromised from the onset. Never mind the steps that I took, setting up two-factor authentication and all… It was never really my wallet to begin with.
The big warning sign was when the crook first processed a “mining fee”. I did not understand the details, but I knew that something was wrong. No third party can take money from your bitcoin wallet, “mining enabled” or otherwise. Yet at the same time, I continued to receive small payments, so I was still waiting for the other shoe to drop.
I guess eventually “Mr. Spark” decided that I am unlikely to invest more into his scheme, but more likely, I was not his only or biggest victim. You don’t set up an elaborate scam like this, with a fake social media account, fake phone number and all to just steal a hundred bucks from someone. (That would be a less effective, and certainly more risky, way of making money than working at minimum wage.)
There is the usual, “if it’s too good to be true” lesson here: Nobody is going to pay you 8% interest a day. OK, I knew that. I also knew that cloud mining is a very risky proposition, the returns are not spectacular and fraud is rampant. I didn’t have to spend a hundred bucks to learn this.
But there is also a valuable technical lesson. I had zero experience with cryptocurrency wallets in the past, and thus I did not realize that anyone setting up the wallet basically has a permanent, irrevocable key to that wallet. And when a sum, however small, goes missing from your bitcoin wallet, it is a guaranteed indicator that the wallet is compromised.
There is also another other thing that I did not realize until today. Namely that the Spark account on Quora is almost certainly a fake, an impersonation. In fact, it was not until I actually asked myself, “how can this chap commit such fraud under his own name?” that I came up instantly with the obvious answer: he didn’t. Rather, a scamster used the name and credentials of a respectable but social media shy expert to set up shop and rip off his victims. That I did not think of this possibility earlier is a consequence of my prejudice. I had very low expectations to begin with, when it comes to people in the speculative cryptocurrency business. So neither the cheap VoIP line nor the pushy behavior raised additional red flags: I was wondering what scam the real Neale Spark was dragging me into, I did not expect to be dealing with an impostor.
*Name altered to protect the privacy and reputation of the person who was impersonated.