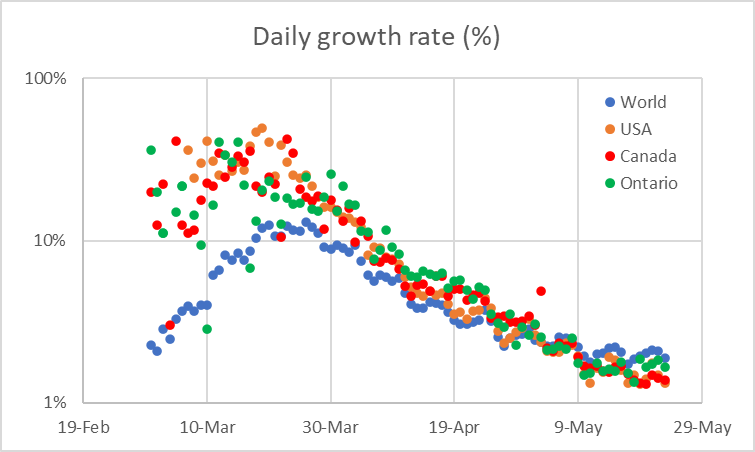
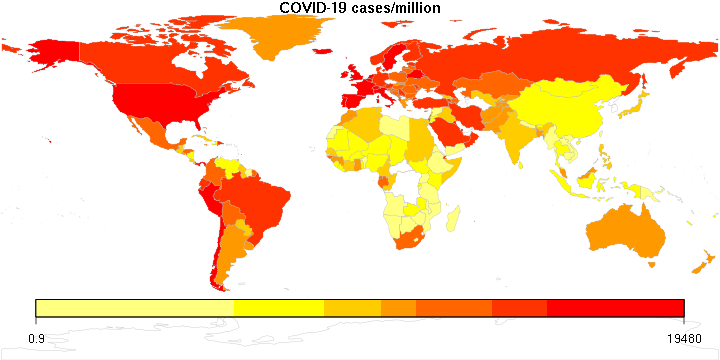
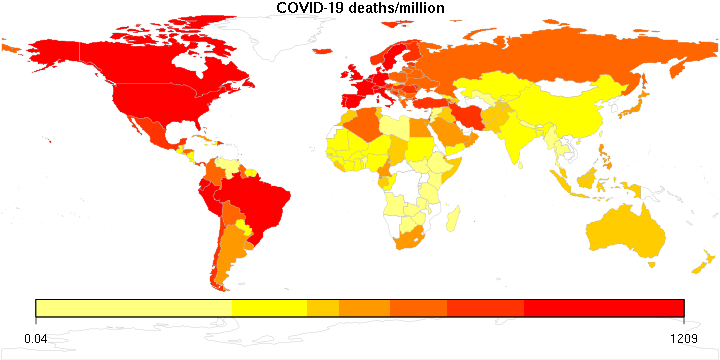
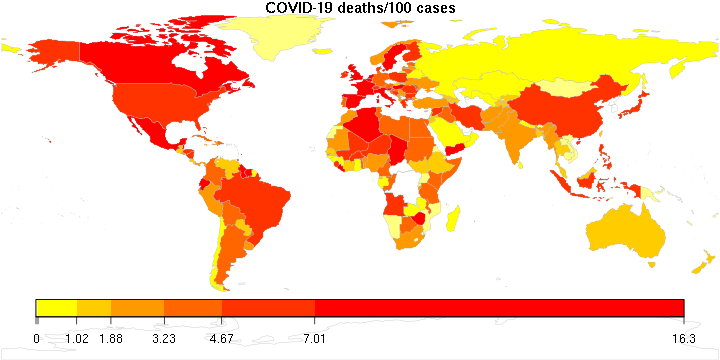
Still playing with some COVID-19 maps, so here is another one: This one ranks countries by the number of COVID-19 cases per 1,000 square kilometers.
What’s the point, you might ask? Well, when there are lots of people confined to a small area, even a few cases can mean trouble; in contrast, when you have many cases but spread over half a continent, you may never come across a single infected person in your travels.
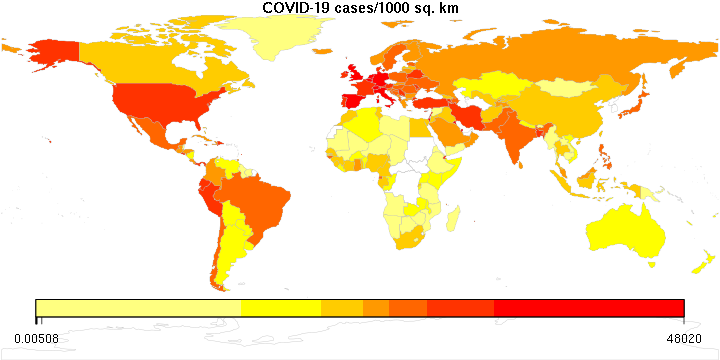
Again, the color legend remains a little whacky; it is logarithmic, but I don’t know how to convince this R package to display it nicely.
The numbers are pretty high. It goes without saying that densely populated microstates like Monaco win the contest, but then there is Qatar (3494), Belgium (1866), the Netherlands (1324), the UK (1051)… numbers that are way too high. For comparison, the USA is at 180, Hungary at 41, Russia at 20 (no surprise there), China at 9 (!), and so is Canada.