Although I tried it, I am not using Claude Code or any of the other “agentic” coding tools provided by AI companies. However, I do use their models as coding assistants. What I don’t need is an “agent” that compiles code, manages git repos, or, well, messes up my system. What I do need is an efficient, extremely knowledgeable coding assistant who can complete in minutes what would take hours, days, perhaps even weeks for me to write.
Take a look at this selection of Web apps I recently created, for my own use, really.
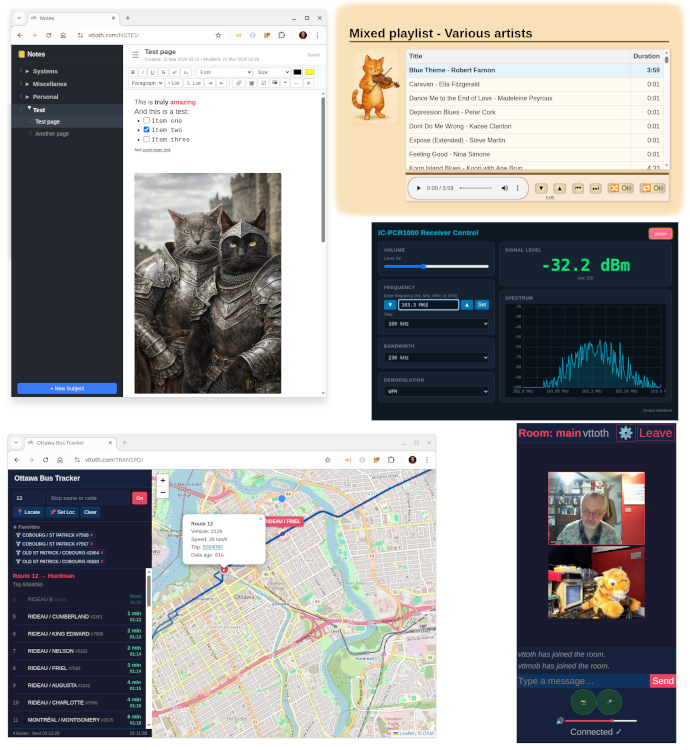
In the upper left, a note-taker app that I have now been using for over a month as my “on premises” replacement of Microsoft OneNote. Works like a charm, better than OneNote in a variety of ways.
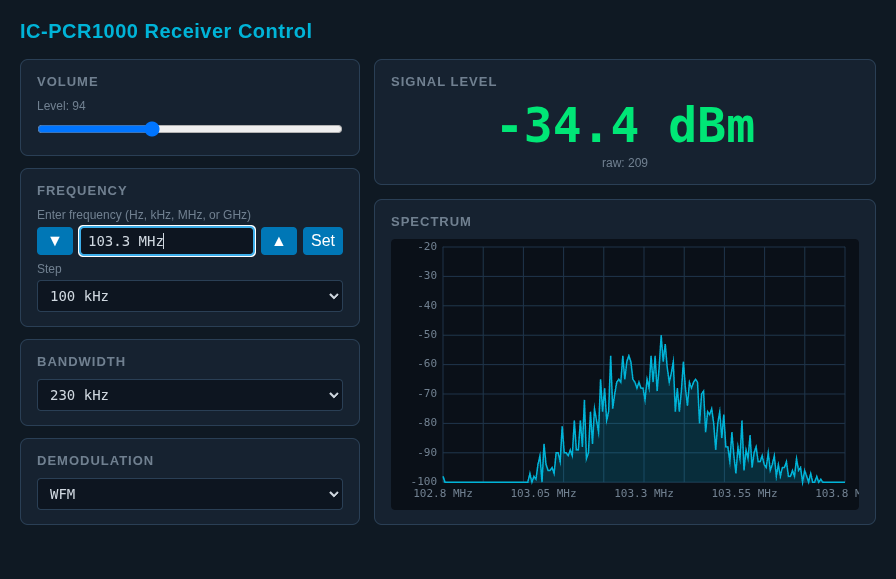
Going clockwise, the next app is my custom music player. It’s integrated with my private library of my ripped CDs. Next is an app that controls my IC-PCR1000 radio. This radio is just a little black box, connected to a PC via a serial cable. (Yes, it’s that old.) It’s an “almost professional grade” communications receiver that basically covers the continuous radio spectrum from 10 kHz to 1.3 GHz. I am not doing anything fancy with it these days, just listening (mostly) to CBC Radio 2 or Radio Canada’s Ici Musique.
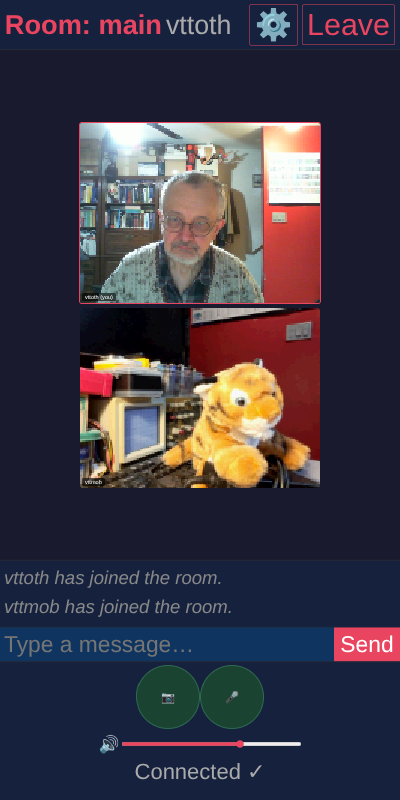
Then there is is a group video chat app that I specifically developed to overcome issues with video not properly transmitted behind firewalls or over VPNs. It’s TCP-only, which of course has its disadvantages, but it works reasonably well. Shown here is the mobile version of its user interface: a plush tiger happily volunteered to be my chat partner in a test.
Finally, a bus tracker app, using real-time data from Ottawa’s public transportation company, OC Transpo. As the data format they use is a Google standard that is now used by many other municipalities, I am thinking of adapting my app to work, e.g., using data from Budapest. For now, it just does what it was supposed to do in the first place, covering Ottawa, with real-time refresh and updates.
For me, this represents the true power of LLMs in software development. None of that agentic nonsense. I don’t need the AI to do typing for me. I need the AI to spit out 1000 lines of mostly correct code in a matter of seconds, saving me countless hours of development time. What it enables is for me to create bespoke software that does exactly what I need it to do. But in the end, I “own” the code, I understand what it does, how it works, I can debug and refine it without AI help if necessary. The agency remains mine.