In recent years, I saw myself mostly as a “centrist liberal”: one who may lean conservative on matters of the economy and state power, but who firmly (very firmly) believes in basic human rights and basic human decency. One who wishes to live in a post-racial society in which your ethnicity or the color of your skin matter no more than the color of your eyes or your hairstyle. A society in which you are judged by the strength of your character. A society in which consenting, loving adults can form families regardless of their gender or sexual orientation. A society that treats heterosexuals and non-heterosexuals alike, without prejudice, without shaming, without rejection. A society in which covert racism no longer affords me “white privilege” while creating invisible barriers to those who come from a different ethnic background.
But then, I read that one of the pressing issues of the day is… the elimination of terms such as “master/slave” or “blacklist/whitelist” from the technical literature and from millions upon millions of lines of software code.
Say what again?
I mean… not too long ago, this was satire. Not too long ago, we laughed when overzealous censors (or was it misguided software?) changed “black-and-white” into “African-American-and-white”. Never did I think that one day, reality catches up with this Monty Pythonesque insanity.
It is one thing to fight for a post-racial society with gender equality. For a society in which homosexuals, transsexuals and others feel fully appreciated as human beings, just like their conventionally heterosexual neighbors. For a society free of overt or covert discrimination.
It is another thing to seek offense where none was intended. To misappropriate terms that, in the technical literature, NEVER MEANT what you suggest they mean. And then, to top it all off, to intimidate people who do not sing exactly the same song as the politically correct choir.
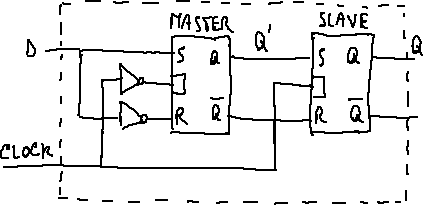
No, I do not claim the right, the privilege, to tell you what terms you should or should not find offensive. I am simply calling you out on this BS. You know that there is/was nothing racist about blacklisting a spammer’s e-mail address or arranging a pair of flip-flops (the electronic components, not the footwear) in a master/slave circuit. But you are purposefully searching for the use of words like “black” or “slave”, in any context, just to fuel this phony outrage. Enough already!
Do you truly want to fight real racism? Racism that harms people every day, that prevents talented young people from reaching their full potential, racism that still shortens lives and makes lives unduly miserable? Racial discrimination remains real in many parts of the world, including North America. Look no further than indigenous communities here in Canada, or urban ghettos or Native American villages in the United States. And elsewhere in the world? The treatment of the Uyghurs in China, the treatment of many ethnic minorities in Russia, human rights abuses throughout Africa and Asia, rising nationalism and xenophobia in Europe.
But instead of fighting to make the world a better place for those who really are in need, you occupy yourselves with this made-up nonsense. And as a result, you achieve the exact opposite of what you purportedly intend. Do you know why? Well, part of the reason is that decent, well-meaning people in democratic countries now vote against “progressives” because they are fed up with your thought police.
No, I do not wish to offer excuses for the real racists, the bona fide xenophobes, the closet nazis and others who enthusiastically support Trump or other wannabe autocrats elsewhere in the world. But surely, you don’t believe that over 70 million Americans who voted for Donald J. Trump 17 days ago are racist, xenophobic closet nazis?
Because if that’s what you believe, you are no better than the real racists, real xenophobes and real closet nazis. Your view of your fellow citizens is a distorted caricature, a hateful stereotype.
No, many of those who voted for Trump; many of those who voted for Biden but denied Democrats their Senate majority; many of those who voted for Biden but voted Democratic congresspeople out of the US Congress: They did so, in part, because you went too far. You are no longer solving problems. You are creating problems where none exist. Worse yet, through “cancel culture” you are trying to silence your critics.
But perhaps this is exactly what you want. Perpetuate the problem instead of solving it. For what would happen to you in a post-racial society with gender equality and full (and fully respected) LGBTQ rights? You would fade back into obscurity. You’d have to find a real job somewhere. You would no longer be able to present yourself as a respected, progressive “community leader”.
Oh, no, we can’t have that! You are a champion of human rights! You are fighting a neverending fight against white supremacism, white privilege, racism and all that! How dare I question the purity of your heart, your intent?
So you do your darnedest best to create conflict where none exists. There is no better example of this than the emergence of the word “cis” as a pejorative term describing… me, among other people, a heterosexual, white, middle-class male, especially one who happens to have an opinion and is unwilling to hide it. Exactly how you are making the world a better place by “repurposing” a word in this manner even as you fight against long-established terminology in the technical literature that you perceive as racist is beyond me. But I have had enough of this nonsense.