There is a wonderful tool out there that works with many of the published large language models and multimodal models: Llama.cpp, a pure C++ implementation of the inference engine to run models like Meta’s Llama or Google’s Gemma.
The C++ implementation is powerful. It allows a 12-billion parameter model to run at speed even without GPU acceleration, and emit 3-4 tokens per second in the generation phase. That is seriously impressive.
There is one catch. Multimodal operation with images requires embedding, which is often the most time-consuming part. A single image may take 45-60 seconds to encode. And in a multi-turn conversation, the image(s) are repeatedly encoded, slowing down the conversation at every turn.
An obvious solution is to preserve the embeddings in a cache and avoid re-embedding images already cached. Well, this looked like a perfect opportunity to deep-dive into the Llama.cpp code base and make a surgical change. A perfect opportunity also to practice my (supposedly considerable) C++ skills, which I use less and less these days.
Well, what can I say? I did it and it works.
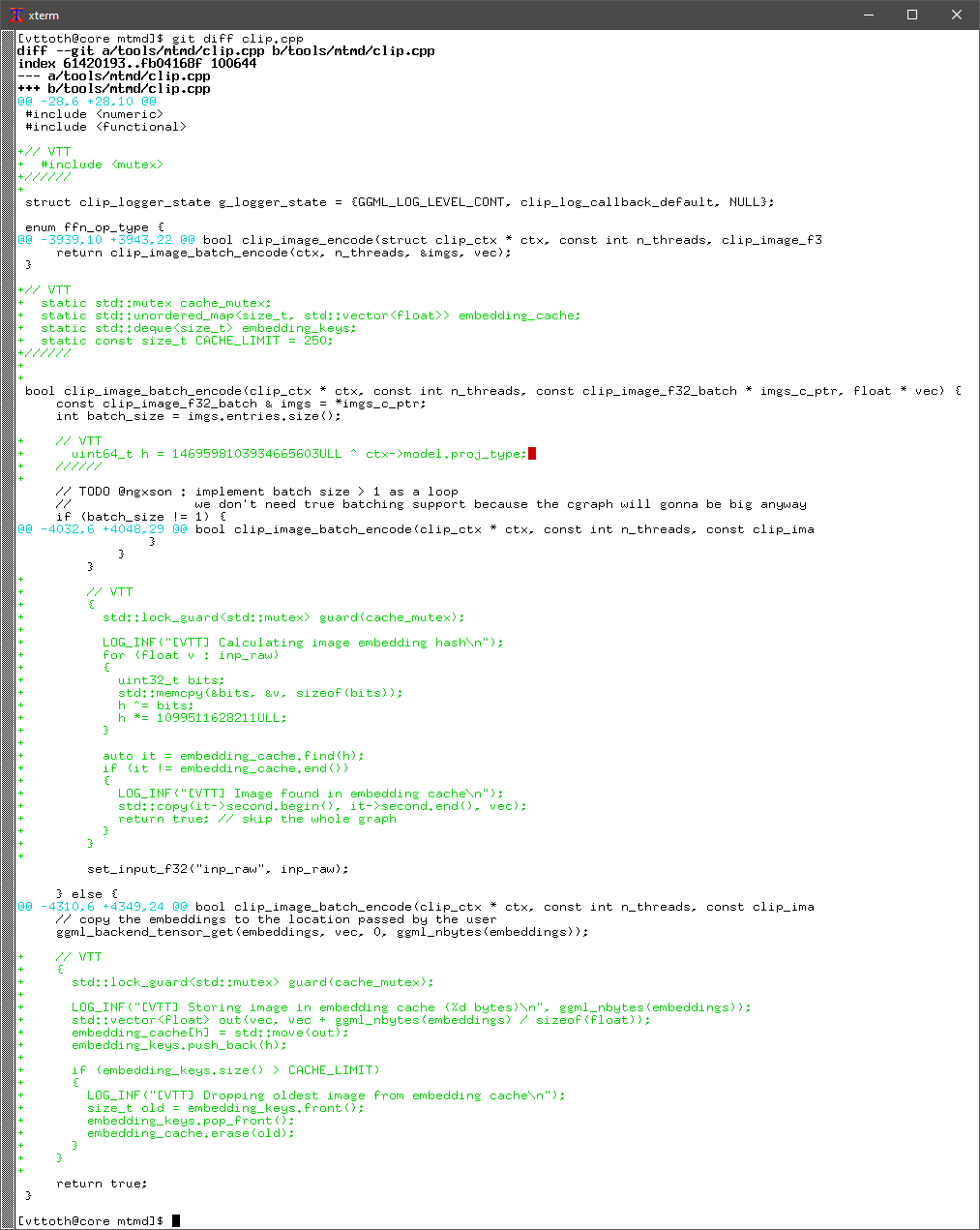
I can now converse with Gemma, even with image content, and it feels much snappier.