I’ve been reading about this topic a lot lately: Retrieval Augmented Generation, the next best thing that should make large language models (LLMs) more useful, respond more accurately in specific use cases. It was time for me to dig a bit deeper and see if I can make good sense of the subject and understand its implementation.
The main purpose of RAG is to enable a language model to respond using, as context, a set of relevant documents drawn from a documentation library. Preferably, relevance itself is established using machine intelligence, so it’s not just some simple keyword search but semantic analysis that helps pick the right subset.
One particular method is to represent documents in an abstract vector space of many dimensions. A query, then, can be represented in the same abstract vector space. The most relevant documents are found using a “cosine similarity search”, which is to say, by measuring the “angle” between the query and the documents in the library. The smaller the angle (the closer the cosine is to 1) the more likely the document is a match.
The abstract vector space in which representations of documents “live” is itself generated by a specialized language model (an embedding model.) Once the right documents are found, they are fed, together with the user’s query, to a generative language model, which then produces the answer.
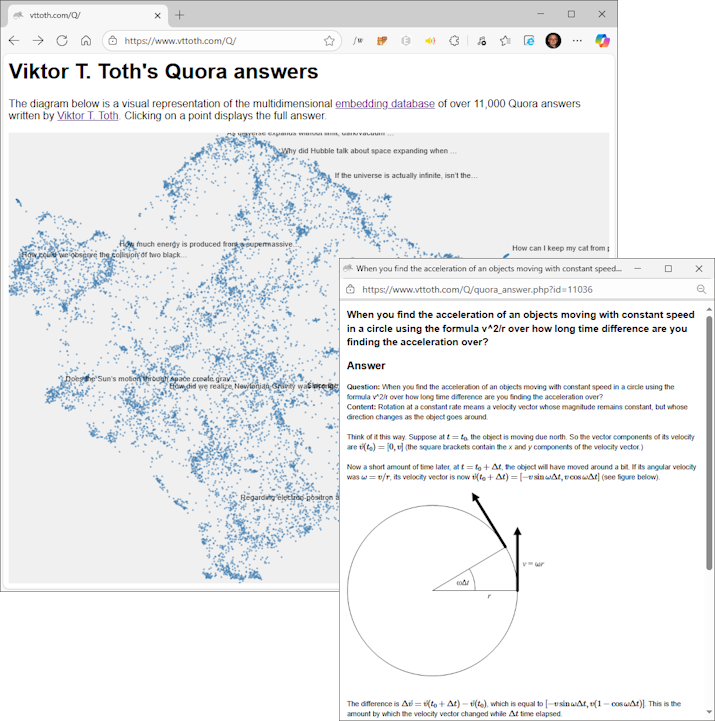
As it turns out, I just had the perfect example corpus for a test, technology demo implementation: My more than 11,000 Quora answers, mostly about physics.
Long story short, I now have this:

The nicest part: This RAG solution “lives” entirely on my local hardware. The main language model is Google’s Gemma with 12 billion parameters. At 4-bit quantization, it fits comfortably within the VRAM of a 16 GB consumer-grade GPU, leaving enough room for the cosine similarity search. Consequently, the model response to queries in record time: the answer page shown in this example was generated in less than about 30 seconds.