The other day, I came across a post, one that has since appeared on several media sites: An Atari 2600 from 1977, running a chess game, managed to beat ChatGPT in a game of chess.
Oh my, I thought. Yet another example of people misconstruing a language model’s capabilities. Of course the Atari beat ChatGPT in a game of chess. Poor ChatGPT was likely asked to keep track of the board’s state in its “head”, and accurately track that state across several moves. That is not what an LLM is designed to do. It is fundamentally a token generator: You feed it text (such as the transcript of the conversation up to the latest prompt) and it generates additional text.
The fact that the text it generates is coherent, relevant, even creative and information-rich is a minor miracle on its own right, but it can be quite misleading. It is easy to sense a personality behind the words, even without the deceptively fine-tuned “alignment” features of ChatGPT. But personality traits notwithstanding, GPT would not be hiding a secret chessboard somewhere, one that it could use to keep track of, and replay, the moves.
But that does not mean GPT cannot play chess, at least at an amateur level. All it needs is a chessboard.
So I ran an experiment: I supplied GPT with a chessboard. Or to be more precise, I wrote a front-end that fed to GPT the current state of the board using a recognized notation (FEN — the Forsyth-Edwards Notation). Furthermore, I only invoked GPT with minimal prompting: the current state of the board and up to two recent moves, instead of the entire chat history.
I used the o3 reasoning model of GPT4.1 for this purpose, which seemed to have been a bit of an overkill; GPT pondered some of the moves for several minutes, even exceeding five minutes in one case. Although it lost in the end, it delivered a credible game against its opponent, GNU Chess playing at “level 2”.
In fact, for a while, GPT seemed to be ahead: I was expecting it to win when it finally made a rather colossal blunder, sacrificing its queen for no good reason. That particular move was a profound outlier: Whereas GPT prefaced all its other moves with commentary and analysis, this particular move was presented with no commentary whatsoever. It’s almost as if it simply decided to sabotage its own game. Or perhaps just a particularly bad luck of the draw by an RNG in what is fundamentally a stochastic reasoning process?
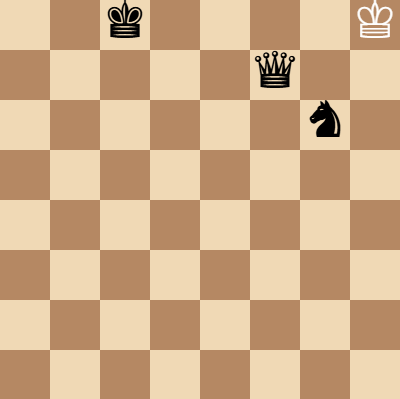
Still, it managed to last for 56 moves against capable chess software. The only other blunder it made during the game was one attempted illegal move that would have left its king in check. A retry attempt yielded a valid move.
I am including a transcript of the game below, as recorded by my interface software. The queen was lost in turn 44.
As I mentioned, I thought that using the o3 model and its reasoning capability was excessive. Since then, I ran another experiment, this time using plain GPT4.1. The result was far less impressive. The model made several attempts at illegal moves, and the legal moves it made were not exactly great; it lost its queen early on, and lost the game in 13 moves. Beginner level, I guess.
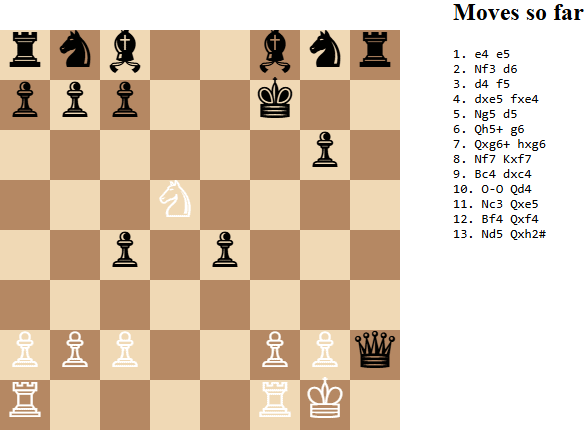
Oh well. So maybe the reasoning model is required, to be able to make GPT play credibly.
Nonetheless, I think these examples demonstrate that while these models are no chess grandmasters, they are not stochastic parrots either. The fact that a language model can, in fact, offer a reasonable game against a dedicated chess software opponent speaks for itself.
Here is the transcript of the 56-move game that the o3 model would have likely won, had it not squandered away its queen.
1. e4 e6 2. d4 d5 3. Nc3 Nf6 4. Bg5 Be7 5. e5 Nd7 6. h4 Bxg5 7. hxg5 Qxg5 8. Nf3 Qd8 9. Bd3 h6 10. O-O a5 11. Nb5 Nb6 12. Rc1 O-O 13. c4 dxc4 14. Bxc4 Bd7 15. Bd3 Bxb5 16. Bxb5 f6 17. Qb3 Qe7 18. exf6 Rxf6 19. Ne5 Qd6 20. Rd1 Kf8 21. Nc4 Nxc4 22. Qxc4 c6 23. Rd3 Rf7 24. Ba4 b5 25. Bxb5 Qd7 26. Qc5+ Ke8 27. d5 cxb5 28. dxe6 Qxe6 29. Re3 Qxe3 30. Qxe3+ Re7 31. Qf3 Ra7 32. Qh5+ Kd8 33. Rd1+ Rd7 34. Qf3 Rxd1+ 35. Qxd1+ Nd7 36. Qd2 b4 37. a3 Re4 38. f3 Rc4 39. b3 Rc3 40. axb4 axb4 41. Qd5 Rc1+ 42. Kh2 g5 43. Qg8+ Kc7 44. Qc8+ Kxc8 45. Kg3 Rc3 46. Kg4 Rxb3 47. Kh5 Rxf3 48. gxf3 b3 49. Kxh6 b2 50. Kxg5 b1=Q 51. Kh6 Qh1+ 52. Kg7 Qxf3 53. Kg8 Ne5 54. Kh8 Qb7 55. Kg8 Qf7+ 56. Kh8 Ng6#
I can almost hear a character, from one of the old Simpson’s episodes, in a scene set in Springfield’s Russian district, yelling loudly as it upturns the board: “Хорошая игра!”
Interesting experiment. Hopefully it is not as dangerous as for Moxon the inventor (you may remember the story “Moxon’s Master” by Ambrose Bierce).
Inspired by this I tried experimenting with DeepSeek and some simpler games but it generally ends up with either it knowing the relevant Sprague-Grundy numbers etc, or situation where it looks tricky to explain game rules.
I guess it is hard to extrapolate to other chess variants, but perhaps you can try for fancy ask it to play on “cylindrical” board or try Fischer random chess.
scene set in Springfield’s Russian district, yelling loudly
Funny. It sounds unnatural, like not ideal calque translation – we normally say “thanks for the game” rather than “good game” (probably due to complicated historic/linguistic reasons). But overall this pretty resembles scene of chess game end in the old soviet movie “Gentlemen of Fortune” when fellows turned chess into hazard game and are trying to win some clothes from stranger (as they lost their own after transportation in the liquified cement cistern by mistake).
This is the scene: https://youtu.be/t-4ADaq9og4 .