When the Rogers outage hit us, especially seeing that equipment remained physically connected but became unreachable for the outside world, I was immediately drawn to the conclusion that this was a cascading configuration error, invalid routes advertised through BGP, not some physical equipment problem or a cyberattack.
I guess I was not wrong (though I should stress that making such a general assessment after the fact from the comfort of my own chair is easy; finding the specific causes and resolving the problem, now that’s the hard part and I’m sure there are more than a few Rogers network engineers whose hair got a bit grayer in the past 48 hours). Cloudflare offered their own analysis, in which they pointed out that indeed, the outage was preceded by a sudden, unexpected burst of BGP advertisements. Here are two plots from Cloudflare’s blog post, montaged together so that the timestamps match:
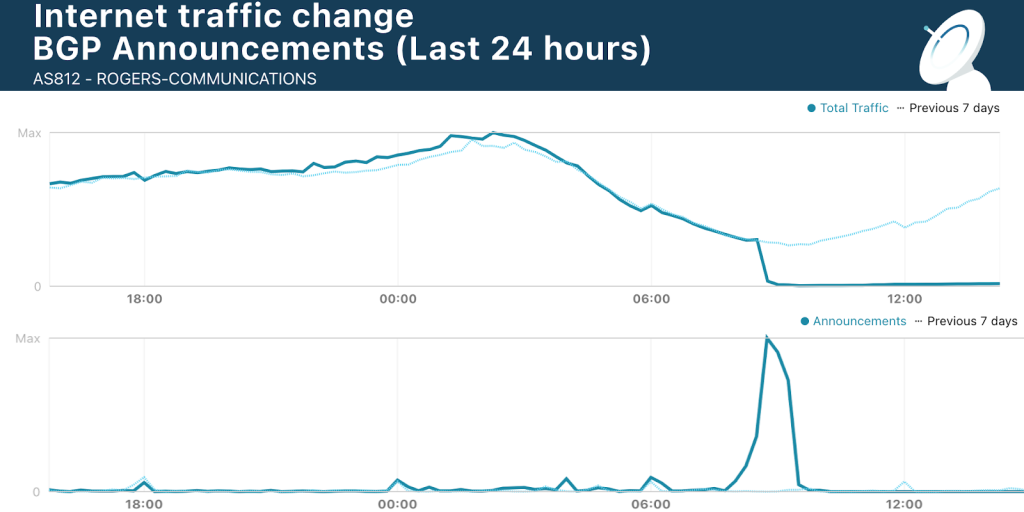
Whatever the specific action was that resulted in this, it is truly spectacular how it killed all of Rogers’s network traffic at around 4:45 AM Friday morning.
Today, things were slowly coming back to normal. But just to add to the fun, earlier this afternoon first my workstation and later, two other pieces of hardware lost all connectivity here on my home office network. What the… Well, it turned out that the router responsible for providing DHCP services needed a kick in the proverbial hind part, in the form of a reboot. Still… Grumble.